
The CPU requirement for the GPQT GPU based model is lower that the one that are optimized for CPU. Edited Completely loaded on VRAM 6300MB took 12 seconds to process 2200 tokens generate a summary 30 tokenssec. Hello Id like to know if 48 56 64 or 92 gb is needed for a cpu setup Supposedly with exllama 48gb is all youd need for 16k Its possible ggml may need more. The performance of an Llama-2 model depends heavily on the hardware. Its likely that you can fine-tune the Llama 2-13B model using LoRA or QLoRA fine-tuning with a single consumer GPU with 24GB of memory and using..
Medium
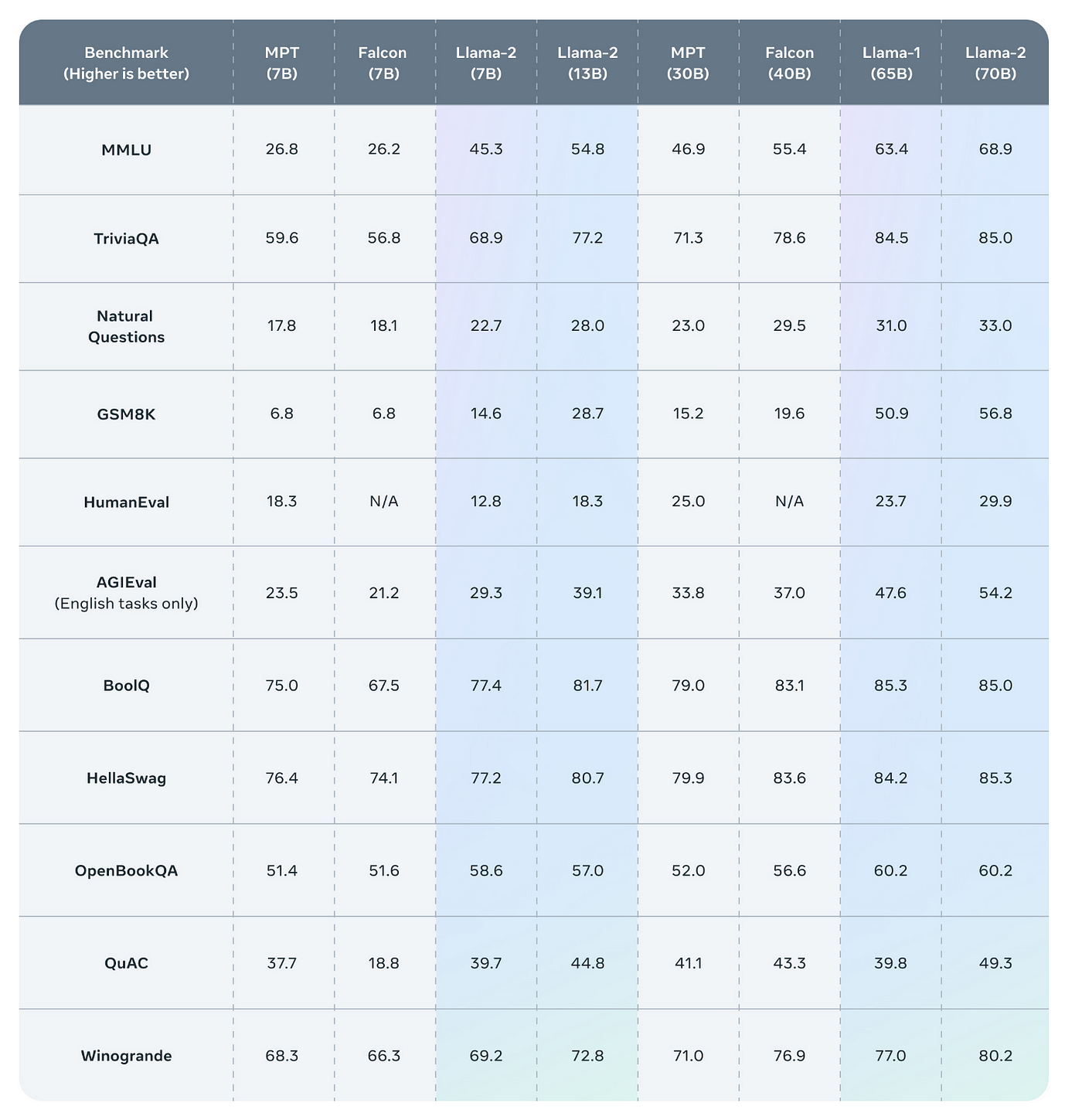
Llama 2 The next generation of our open source large language model available for free for research and commercial use. Use Google Colab to get access to an Nvidia T4 GPU for free Use Llama cpp to compress and load the Llama 2 model onto GPU. Llama 2 outperforms other open source language models on many external benchmarks including reasoning coding proficiency and knowledge tests. For those eager to harness its capabilities there are multiple avenues to access Llama 2 including the Meta AI website Hugging Face. Run Llama 2 with an API Llama 2 is a language model from Meta AI Its the first open source language model of the same caliber as OpenAIs..
Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets Send me a message or upload an. Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion tokens and fine-tuned with over a million human. Ask any question to two anonymous models eg ChatGPT Claude Llama and vote for the better one You can continue chatting until you identify a winner. Llama 2 7B13B are now available in Web LLM Try it out in our chat demo Llama 2 70B is also supported If you have a Apple Silicon Mac with 64GB or more memory you. To download Llama 2 model artifacts from Kaggle you must first request a using the same email address as your Kaggle account After doing so you can request access to models..
Github
For optimal performance with LLaMA-13B a GPU with at least 10GB VRAM is. Llama-2-13b-chatggmlv3q4_0bin offloaded 4343 layers to GPU Llama-2-13b-chatggmlv3q4_0bin offloaded 4343 layers to GPU. If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre. Its likely that you can fine-tune the Llama 2-13B model using LoRA or QLoRA fine-tuning with a single consumer GPU with 24GB of memory and using QLoRA requires even less GPU memory and. For beefier models like the llama-13b-supercot-GGML youll need more powerful hardware If youre using the GPTQ version youll want a strong..



Comments